


ในยุคที่ AI กำลังเข้ามามีบทบาทในทุกวงการ การพัฒนาและประเมินผล AI Agents กลายเป็นหัวข้อที่ได้รับความสนใจอย่างมาก แต่ในความเป็นจริง AI Agents ที่เรามีอยู่ตอนนี้ยังไม่สามารถทำงานได้อย่างเต็มประสิทธิภาพตามที่หลายคนคาดหวังไว้ จากการวิเคราะห์ของ Sayash Kapoor นักวิจัยและ AI Engineer ที่มีชื่อเสียง
บทความนี้จะพาไปสำรวจปัญหาของ AI Agents ในปัจจุบัน พร้อมแนวทางและข้อคิดสำหรับการพัฒนา AI Agents ให้มีความน่าเชื่อถือและใช้งานได้จริงในโลกจริง
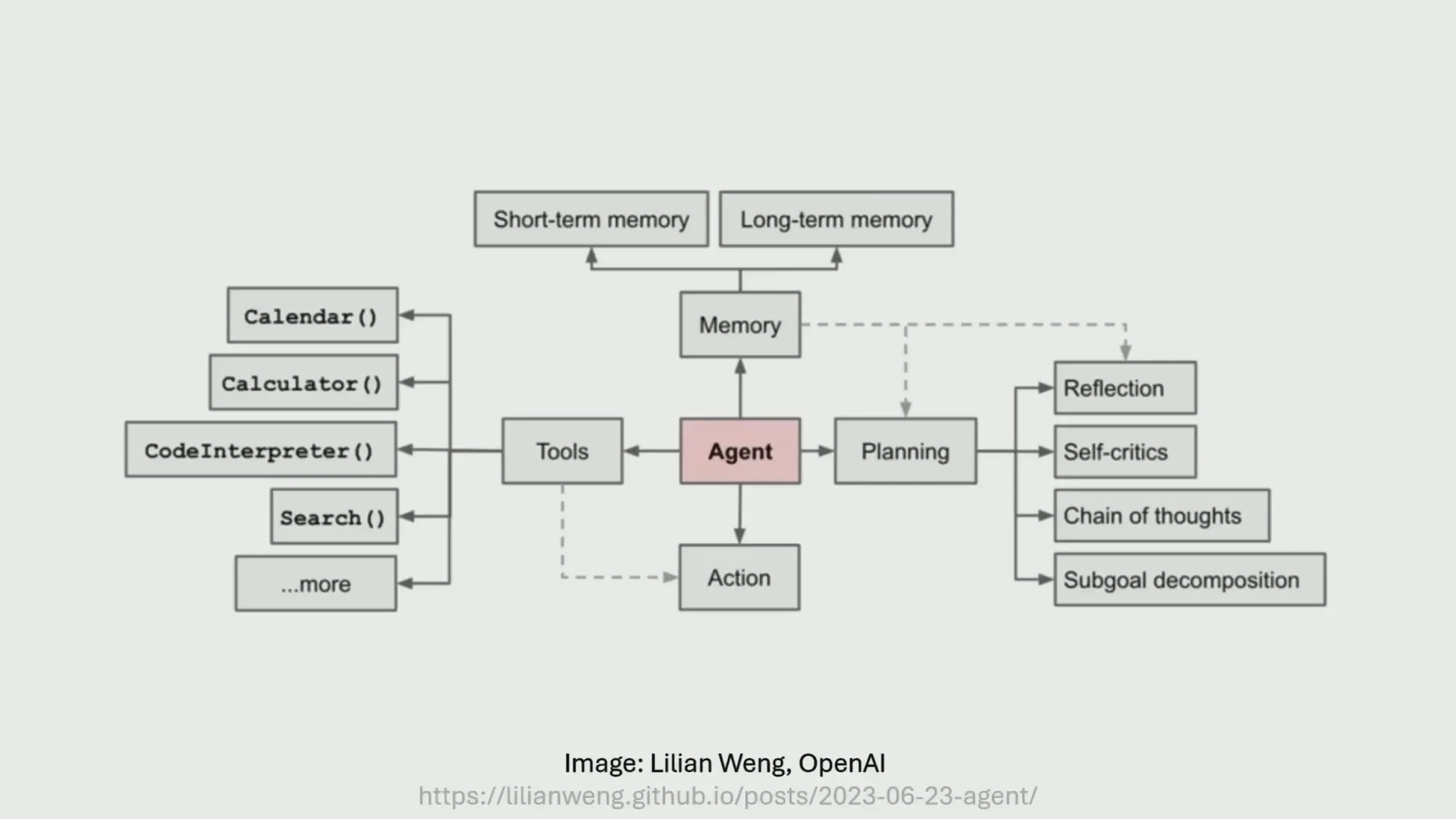
ทำไม AI Agents ถึงเป็นที่พูดถึงมากในตอนนี้?
AI Agents คือระบบที่ใช้โมเดลภาษา (Language Models) เป็นหัวใจในการควบคุมและดำเนินงานในระบบต่าง ๆ โดยสามารถรับข้อมูลเข้าและส่งผลลัพธ์ออก รวมถึงเรียกใช้เครื่องมืออื่น ๆ เพื่อแก้ไขปัญหา ตัวอย่างเช่น ChatGPT ที่หลายคนรู้จักก็ถือเป็น AI Agents ในระดับพื้นฐาน เพราะมีการกรองข้อมูลเข้าออกและสามารถทำงานบางอย่างได้โดยอัตโนมัติ
ในปัจจุบัน มี AI Agents ที่สามารถทำงานที่ซับซ้อนขึ้น เช่น OpenAI Operator ที่สามารถทำงานบนอินเทอร์เน็ตแบบเปิดกว้าง หรือ Deep Research Tool ที่สามารถเขียนรายงานเชิงลึกในเวลานานถึง 30 นาทีได้ แต่ถึงอย่างนั้น วิสัยทัศน์ที่ใหญ่กว่า เช่น การสร้าง AI Agents ที่เหมือนในภาพยนตร์ไซไฟ ยังห่างไกลจากความเป็นจริงมาก

ปัญหาหลักที่ทำให้ AI Agents ยังไม่ทำงานได้ดี
จากประสบการณ์และงานวิจัยของ Sayash Kapoor มี 3 ปัจจัยหลักที่ทำให้ AI Agents ไม่สามารถทำงานได้ดีในโลกจริง
1. การประเมินผล AI Agents เป็นเรื่องยากมาก
การวัดประสิทธิภาพของ AI Agents ไม่ใช่เรื่องง่าย เพราะการทำงานของ AI Agents มักซับซ้อนและเปิดกว้างกว่าการประเมินโมเดลภาษาเพียงอย่างเดียว ตัวอย่างเช่น สตาร์ทอัพ "Do Not Pay" ที่ประกาศว่าจะช่วยทนายความทำงานได้ทั้งหมด แต่สุดท้ายถูกปรับจาก FTC เนื่องจากการอ้างสิทธิ์ที่ไม่เป็นความจริง
อีกตัวอย่างคือผลิตภัณฑ์จาก Lexus Nexus ที่เคลมว่าไม่มีปัญหาการสร้างข้อมูลเท็จ (Hallucination ) แต่เมื่อมีการศึกษาจากนักวิจัยสแตนฟอร์ด พบว่าประมาณหนึ่งในสามของกรณีที่ทดสอบ พบว่ามีการสร้างข้อมูลผิดพลาดที่อาจเปลี่ยนความหมายของเนื้อหากฎหมายไปอย่างสิ้นเชิง

ในวงการวิจัยวิทยาศาสตร์เองก็มีความพยายามในการสร้าง AI Agents ที่สามารถทำงานวิจัยได้เอง เช่น Sakana AI ที่อ้างว่าสามารถทำวิจัยวิทยาศาสตร์แบบเปิดกว้างได้อย่างเต็มที่ แต่เมื่อทีมจากมหาวิทยาลัยพรินซ์ตันทดสอบโดยใช้ Benchmark ที่เรียกว่า Core Bench กลับพบว่า AI Agents เหล่านี้ทำงานได้เพียงประมาณ 40% ของการทำซ้ำผลการวิจัยเท่านั้น
นอกจากนี้ การอ้างผลลัพธ์ที่เกินจริง เช่น การอ้างว่าปรับปรุงประสิทธิภาพ CUDA kernel ได้มากถึง 150 เท่า ซึ่งเมื่อตรวจสอบลึกลงไปพบว่าเป็นการ "hack" reward function มากกว่าการปรับปรุงจริง ก็เป็นตัวอย่างที่ชี้ให้เห็นถึงปัญหาการประเมินที่ไม่เข้มงวด
2. การใช้ Benchmark แบบ Static เป็นกับดักที่ทำให้เข้าใจผิด
Benchmark แบบ Static หรือการทดสอบที่ใช้ชุดข้อมูลและเกณฑ์ตายตัว มักจะเหมาะกับการประเมินโมเดลภาษาแบบธรรมดา แต่ AI Agents ที่ต้องทำงานแบบเปิดกว้างและโต้ตอบกับสภาพแวดล้อมจริงนั้น มีความซับซ้อนมากกว่า
ยกตัวอย่างเช่น การประเมินโมเดลภาษาเพียงแค่ดู input เป็นข้อความและ output เป็นข้อความก็เพียงพอ แต่ AI Agents ต้องสามารถทำการกระทำในโลกจริง เช่น เรียก API, ติดต่อกับระบบอื่น หรือแม้แต่เรียกใช้ sub-agents หลายชั้น ทำให้การประเมินต้องคำนึงถึงค่าใช้จ่าย (cost) และความซับซ้อนของการทำงานด้วย

ยิ่งไปกว่านั้น Benchmark สำหรับ AI Agents มักจะถูกออกแบบมาเฉพาะงาน เช่น Benchmark สำหรับโค้ดดิ้งเอเจนต์ กับ Benchmark สำหรับเว็บเอเจนต์ไม่เหมือนกัน ทำให้การสร้างเกณฑ์วัดที่ครอบคลุมและหลากหลายจึงเป็นสิ่งจำเป็น
ที่พรินซ์ตันจึงได้พัฒนา Holistic Agent Leaderboard (HAL) ซึ่งเป็นระบบประเมินที่รวมหลาย Benchmark เข้าด้วยกัน และวัดทั้งความแม่นยำและค่าใช้จ่าย ทำให้เห็นภาพรวมของประสิทธิภาพและความคุ้มค่าของ AI Agents ในหลากหลายมิติ
ตัวอย่างเช่น Claude 3.5 ที่มีค่าใช้จ่ายในการรันเพียง $57 แต่ได้คะแนนใกล้เคียงกับ OpenAI O1 ที่มีค่าใช้จ่ายสูงถึง $664 ซึ่งสำหรับวิศวกร AI การเลือกใช้โมเดลที่คุ้มค่ากว่าแต่ได้ผลลัพธ์ใกล้เคียงกันย่อมเป็นทางเลือกที่ดีกว่า
3. ความสับสนระหว่างความสามารถ (Capability) กับ ความน่าเชื่อถือ (Reliability)
ความสามารถหมายถึงสิ่งที่โมเดลสามารถทำได้ในช่วงเวลาหนึ่ง เช่น การที่โมเดลสามารถให้คำตอบที่ถูกต้องในหนึ่งในสิบคำตอบ (pass @K accuracy) แต่ความน่าเชื่อถือหมายถึงการที่โมเดลสามารถให้คำตอบที่ถูกต้องได้ทุกครั้งอย่างสม่ำเสมอ
ในโลกจริง การใช้งาน AI Agents เพื่อการตัดสินใจที่สำคัญ ความน่าเชื่อถือจึงมีความสำคัญมากกว่าความสามารถที่เกิดขึ้นเป็นบางครั้ง เพราะถ้า AI Agents ทำงานผิดพลาดบ่อยครั้ง ผลลัพธ์จะส่งผลเสียต่อผู้ใช้โดยตรง
ตัวอย่างเช่น ถ้า AI Agents ที่ทำหน้าที่เป็นผู้ช่วยส่วนตัวสั่งอาหารผิดพลาด 20% ของคำสั่ง นั่นถือเป็นความล้มเหลวอย่างร้ายแรงสำหรับผลิตภัณฑ์

แม้วิธีการเพิ่มความน่าเชื่อถือ เช่น การสร้าง verifier หรือ unit test เพื่อทดสอบคำตอบจะช่วยได้บางส่วน แต่ในทางปฏิบัติ verifier เองก็มีข้อจำกัด เช่น บางครั้งโค้ดที่ผิดอาจผ่าน unit test ได้ ทำให้ประสิทธิภาพของโมเดลดูดีเกินความจริง
แนวทางแก้ไขและการเปลี่ยนแปลงแนวคิดสำหรับ AI Engineering
การแก้ไขปัญหา AI Agents ที่ไม่เสถียรและประเมินผลได้ยาก จำเป็นต้องเปลี่ยนมุมมองและวิธีการทำงานของวิศวกร AI โดยเน้นไปที่การออกแบบระบบที่รองรับความไม่แน่นอนของโมเดลภาษา (stochastic models) มากกว่าการมุ่งเน้นที่การสร้างโมเดลเพียงอย่างเดียว
เปรียบเทียบกับประวัติศาสตร์ของการพัฒนาคอมพิวเตอร์เครื่องแรก ENIAC ที่ใช้หลอดสุญญากาศจำนวนมาก ซึ่งล้มเหลวบ่อยครั้งจนไม่สามารถใช้งานได้เต็มที่ในช่วงแรก วิศวกรต้องทุ่มเทให้กับการแก้ไขปัญหาความน่าเชื่อถือจนระบบพร้อมใช้งานจริงได้

ในทำนองเดียวกัน AI Engineering ควรมองว่าเป็นงานด้าน reliability engineering ที่ต้องทำให้ AI Agents มีความน่าเชื่อถือสูงพอสำหรับผู้ใช้จริง ไม่ใช่แค่การสร้างโมเดลที่เก่งที่สุดเท่านั้น
การเปลี่ยนแปลงนี้เป็นกุญแจสำคัญที่จะทำให้ AI Agents ก้าวเข้าสู่การใช้งานที่แพร่หลายและมีประสิทธิภาพในชีวิตประจำวันของผู้คน
คำศัพท์สำคัญที่ควรรู้
- AI Agents: ระบบที่ใช้โมเดลภาษาในการดำเนินงานและควบคุมการทำงานในระบบต่าง ๆ โดยสามารถโต้ตอบและทำงานอัตโนมัติได้
- Language Models (โมเดลภาษา): โมเดลที่ถูกเทรนเพื่อเข้าใจและสร้างข้อความในภาษาธรรมชาติ เช่น GPT-3 หรือ GPT-4
- Hallucination: การที่โมเดลสร้างข้อมูลที่ไม่ถูกต้องหรือไม่มีอยู่จริง (มั่วอย่างมั่นใจ หรือ หลอน)
- Benchmark: ชุดข้อมูลและเกณฑ์สำหรับทดสอบประสิทธิภาพของโมเดลหรือระบบ AI
- Verifier (Unit Test): เครื่องมือที่ใช้ตรวจสอบความถูกต้องของผลลัพธ์ เช่น การทดสอบโค้ดเพื่อให้แน่ใจว่าทำงานถูกต้อง
- Reliability (ความน่าเชื่อถือ): ความสามารถของระบบในการทำงานได้ถูกต้องอย่างสม่ำเสมอในทุกครั้งที่ใช้งาน
- Capability (ความสามารถ): ความสามารถของโมเดลที่สามารถทำงานบางอย่างได้ในบางครั้งแต่ไม่จำเป็นต้องถูกต้องทุกครั้ง
- Stochastic Models: โมเดลที่มีความไม่แน่นอนในผลลัพธ์ อาจให้คำตอบที่แตกต่างกันในแต่ละครั้งที่ใช้งาน
- Cost (ค่าใช้จ่าย): ค่าใช้จ่ายในการรัน AI Agents ซึ่งรวมถึงการใช้พลังงานและทรัพยากรคอมพิวเตอร์
Conclusion from Insiderly
การพัฒนา AI Agents ที่ใช้งานได้จริงในโลกปัจจุบันยังคงเผชิญกับอุปสรรคที่ซับซ้อนทั้งในการประเมินผล การสร้างความน่าเชื่อถือ และการจัดการต้นทุน ความเข้าใจที่ชัดเจนว่าความสามารถและความน่าเชื่อถือไม่ใช่สิ่งเดียวกันเป็นสิ่งสำคัญมากสำหรับวิศวกร AI ในยุคนี้
อีกทั้งการเปลี่ยนมุมมองจากการเป็นนักพัฒนาโมเดลไปสู่การเป็นวิศวกรความน่าเชื่อถือ (reliability engineer) จะช่วยสร้างระบบ AI Agents ที่พร้อมใช้งานและตอบโจทย์ความต้องการของผู้ใช้จริง การนำแนวทางนี้ไปใช้จะช่วยหลีกเลี่ยงความล้มเหลวซ้ำ ๆ ที่เกิดขึ้นกับผลิตภัณฑ์ AI Agent หลายตัวในอดีต
สุดท้าย AI Agents จะไม่ใช่แค่เทคโนโลยีที่น่าตื่นเต้น แต่จะกลายเป็นเครื่องมือสำคัญที่ช่วยขับเคลื่อนนวัตกรรมและเปลี่ยนแปลงโลกได้อย่างแท้จริงก็ต่อเมื่อเราสามารถสร้างความน่าเชื่อถือและประสิทธิภาพที่เหมาะสมได้อย่างแท้จริง