

ในยุคที่เทคโนโลยี AI กำลังก้าวหน้าอย่างรวดเร็ว โมเดลภาษาขนาดใหญ่ (Large Language Models หรือ LLMs) ได้กลายเป็นเครื่องมือสำคัญในการประมวลผลและสร้างภาษามนุษย์ อย่างไรก็ตาม LLMs ประสบปัญหาที่ไม่สามารถเรียนรู้ข้อมูลใหม่ ๆ ที่เกิดขึ้นหลังจากวันที่ตัดข้อมูลของโมเดล (หรือ knowledge cutoff date)
have งานวิจัยหนึ่ง ได้นำเสนอวิธีการแก้ปัญหานี้ด้วยเทคนิค "การเทรนแบบมีผู้สอน" (Supervised Fine-Tuning หรือ SFT) เพื่อให้ LLMs เรียนรู้และเข้าใจข้อมูลใหม่อย่างมีประสิทธิภาพ
วิธีการศึกษา
นักวิจัยทดลองใช้ข้อมูลจากเหตุการณ์กีฬาที่เกิดขึ้นในปี 2023 เช่น ฟุตบอลโลกหญิง และซูเปอร์โบวล์ เพื่อสร้างชุดข้อมูลสำหรับเทรน LLMs โดยแบ่งวิธีการสร้างชุดข้อมูลออกเป็น 2 แบบ:
- แบบใช้โทเคน (Token-based): สร้างคู่คำถาม-คำตอบตามจำนวนคำในเอกสาร เหมาะสำหรับข้อมูลที่มีความยาวและต้องการความครอบคลุม
- แบบใช้ข้อเท็จจริง (Fact-based): เน้นการสร้างคู่คำถาม-คำตอบที่ครอบคลุมข้อเท็จจริงทั้งหมดในเอกสาร เหมาะสำหรับข้อมูลที่ต้องการความถูกต้องและแม่นยำ
นักวิจัยใช้โมเดล GPT-4 ซึ่งมีความรู้จำกัดถึงเดือนกันยายน 2021 มาเทรนด้วยชุดข้อมูลที่สร้างขึ้น โดยใช้เทคนิค LoRA (Low-Rank Adaptation) เพื่อเร่งกระบวนการเทรนและทำให้ใช้ทรัพยากรน้อยลง โดย LoRA ทำงานโดยการประมาณค่าการเปลี่ยนแปลงของ Weight Matrix ด้วย Low-Rank Matrices ซึ่งสามารถคำนวณได้ดังนี้:
```
W = W0 + BA
```
โดยที่ `W0` คือ Weight Matrix เดิม, `B` และ `A` คือ Low-Rank Matrices และ `W` คือ Weight Matrix ที่ถูกปรับปรุงแล้ว
ผลการศึกษา
- SFT ปรับปรุง LLMs ได้จริง: การทดลองแสดงให้เห็นว่า SFT สามารถเพิ่มความสามารถของ LLMs ในการตอบคำถามเกี่ยวกับข้อมูลใหม่ได้อย่างนัยสำคัญ
- วิธีสร้างชุดข้อมูลมีผล: ชุดข้อมูลแบบใช้ข้อเท็จจริงให้ผลลัพธ์ดีกว่าแบบใช้โทเคน เนื่องจากครอบคลุมข้อมูลอย่างทั่วถึงและลดความเสี่ยงที่โมเดลจะหลงทางในข้อมูลที่ไม่เกี่ยวข้อง
- เปรียบเทียบกับ RAG: แม้ว่า SFT จะไม่สามารถเอาชนะการค้นหาข้อมูลจากฐานข้อมูลภายนอก (Retrieval-Augmented Generation หรือ RAG) ได้ แต่ SFT มีความสามารถในการจดจำข้อมูลโดยไม่ต้องพึ่งพาการค้นหา ทำให้ตอบคำถามได้รวดเร็วและใช้ทรัพยากรน้อยกว่า
- การปรับแต่งพารามิเตอร์: การปรับแต่งพารามิเตอร์ เช่น อัตราการเรียนรู้ (learning rate) และจำนวนรอบการฝึก (epochs) มีผลต่อประสิทธิภาพของโมเดลอย่างมาก โดยควรเลือกค่าที่เหมาะสมกับชุดข้อมูลและโมเดลที่ใช้
ข้อจำกัดของการศึกษา
การศึกษานี้มีข้อจำกัดที่ควรพิจารณา:
- ขนาดและประเภทของชุดข้อมูล: ชุดข้อมูลที่ใช้ในการเทรนอาจไม่ครบถ้วน การใช้ชุดข้อมูลที่ใหญ่และหลากหลายมากขึ้นอาจให้ผลลัพธ์ที่แตกต่างกัน
- การเลือกโมเดล: การใช้ GPT-4 เป็นโมเดลพื้นฐานอาจมีผลต่อผลลัพธ์ การทดลองกับโมเดลอื่น ๆ เช่น Llama 2 หรือ Bard อาจให้ข้อมูลเชิงลึกที่แตกต่าง
- ความสามารถในการ generalization: โมเดลที่ถูกเทรนด้วย SFT อาจมีความสามารถในการ generalization ที่จำกัด ทำให้ไม่เหมาะกับข้อมูลประเภทอื่น
- Bias: ชุดข้อมูลที่ใช้ในการเทรนอาจมี bias ส่งผลให้โมเดลสร้างผลลัพธ์ที่ไม่เป็นกลาง
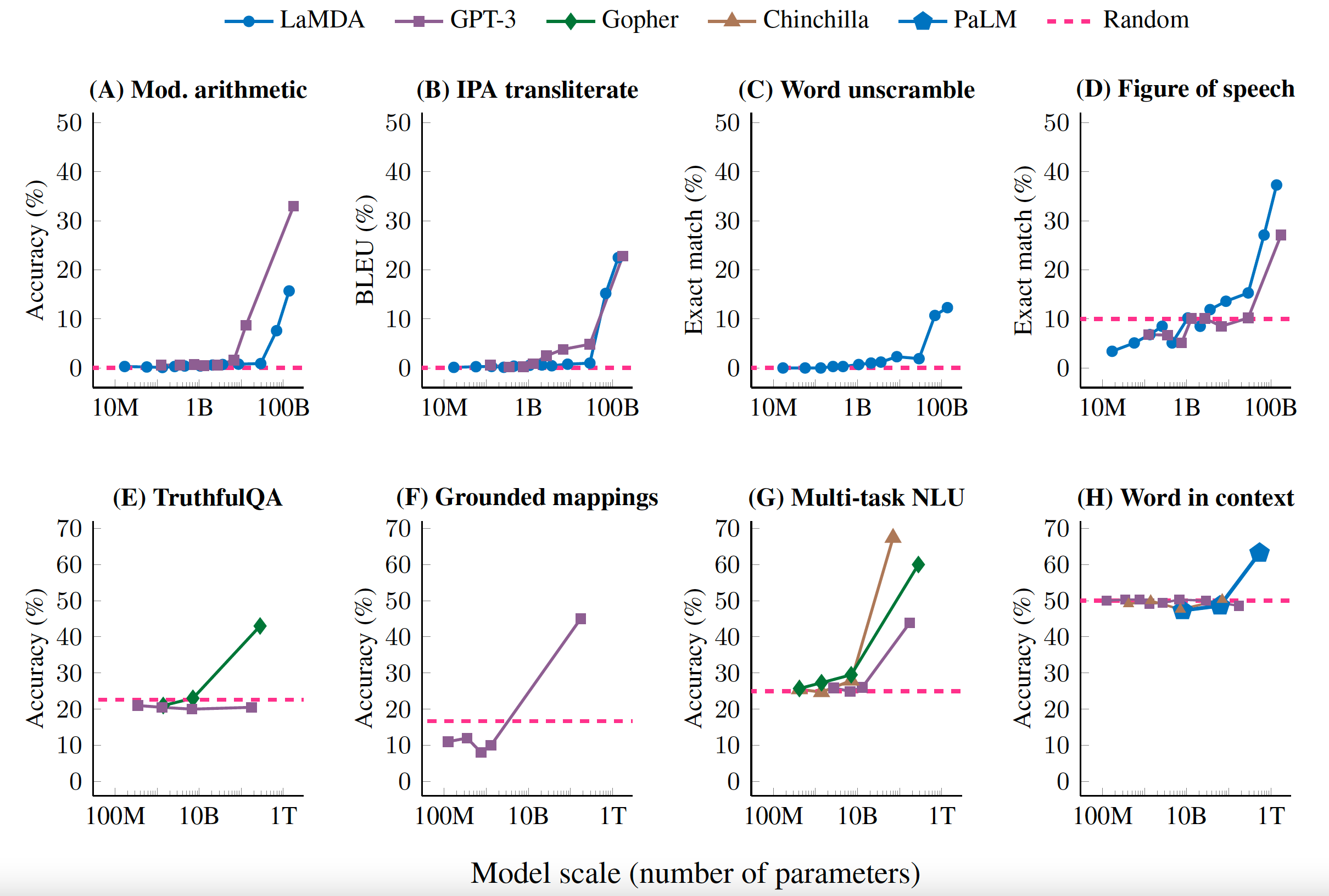
ภาพตัวอย่างประสิทธิภาพของ LLMs เทียบกับขนาดของโมเดล แสดงให้เห็นถึงความสำคัญของการเพิ่มขนาดโมเดลในการปรับปรุงประสิทธิภาพ
ความสำคัญและการนำไปใช้
งานวิจัยนี้มีความสำคัญต่อการพัฒนา AI และ LLMs ในโลกจริง โดยเฉพาะในด้านที่ต้องการข้อมูลทันสมัย เช่น:
- ข่าวสารและเหตุการณ์ปัจจุบัน: LLMs ที่ปรับปรุงด้วย SFT สามารถให้ข้อมูลที่ทันสมัยเกี่ยวกับเหตุการณ์ล่าสุดได้ดีขึ้น เช่น การสรุปข่าว การวิเคราะห์เหตุการณ์
- การวิเคราะห์ตลาดและแนวโน้มธุรกิจ: โมเดลสามารถเรียนรู้และวิเคราะห์ข้อมูลใหม่ ๆ ในตลาดได้อย่างรวดเร็ว เช่น การคาดการณ์แนวโน้มราคา การวิเคราะห์ความรู้สึกของลูกค้า
- การวิจัยทางวิทยาศาสตร์: LLMs สามารถอัพเดตความรู้เกี่ยวกับการค้นพบใหม่ ๆ ทางวิทยาศาสตร์ได้อย่างต่อเนื่อง เช่น การสรุปงานวิจัย การค้นหาความสัมพันธ์ระหว่างข้อมูล
- การศึกษาและการเรียนรู้: ระบบ AI ที่ใช้ในการศึกษาสามารถปรับปรุงเนื้อหาให้ทันสมัยอยู่เสมอ เช่น การสร้างแบบฝึกหัด การให้คำแนะนำ
LLMs ที่ได้รับการปรับปรุงด้วย SFT สามารถนำไปใช้ในผลิตภัณฑ์ต่าง ๆ เช่น ChatGPT, Bard หรือ Llama 2 เพื่อให้มีความสามารถในการตอบคำถามอย่างทันสมัยและแม่นยำมากขึ้น
ประเด็นด้านจริยธรรม
การพัฒนาและใช้งาน LLMs ที่มีการปรับปรุงอย่างต่อเนื่องต้องคำนึงถึงประเด็นด้านจริยธรรมที่สำคัญ ได้แก่:
- การจัดการข้อมูลที่อาจไม่ถูกต้องหรือไม่เป็นจริง
- ความเสี่ยงในการนำไปใช้สร้างเนื้อหา Deepfake หรือการละเมิดลิขสิทธิ์ และ
- การตรวจสอบ bias ที่อาจเกิดขึ้นในผลลัพธ์
สรุป
การพัฒนานี้เป็นก้าวสำคัญในการทำให้ AI มีความยืดหยุ่นและปรับตัวได้มากขึ้น
สามารถรับมือกับโลกที่เปลี่ยนแปลงเร็วขึ้นได้ดียิ่งขึ้น
อย่างไรก็ตาม ยังมีความท้าทายในการพัฒนาวิธีการเทรนที่มีประสิทธิภาพมากขึ้น และการหาสมดุลระหว่างการเรียนรู้ข้อมูลใหม่กับการรักษาความรู้เดิม
ในอนาคต เราอาจเห็นการพัฒนา LLMs ที่สามารถเรียนรู้และปรับตัวได้อย่างต่อเนื่อง ซึ่งจะเป็นประโยชน์ในการสร้างระบบ AI ที่ฉลาดและทันสมัยอยู่เสมอ
แชทคุยถามตอบกับเปเปอร์งานวิจัยที่นี่